
Распознавание образов с камеры с использованием библиотеки OpenCV 3 в реальном времени.
В качестве платформы используется Raspberry Pi, и прекомпилированная база? Caffe
Загружаем необходимые библиотеки:
1 2 3 4 5 6 7 | import numpy as np import argparse import cv2 from imutils.video import VideoStream from imutils.video import FPS import time import imutils |
Numpy — библиотека для работы с массивами
Argparse — библиотка для работы с аргументами командной строки
Cv2 — библиотека OpenCV 3
Imutils — библиотека для работы с изображениями
Добавляем обработку аргументов командной строки:
1 2 3 4 5 6 7 8 | ap = argparse.ArgumentParser() ap.add_argument("-p", "--prototxt", required=True, help="path to Caffe 'deploy' prototxt file") ap.add_argument("-m", "--model", required=True, help="path to Caffe pre-trained model") ap.add_argument("-c", "--confidence", type=float, default=0.2, help="minimum probability to filter weak detections") args = vars(ap.parse_args()) |
Инициализируем список меток класса MobileNet SSD который был обучен заранее, а затем создадим набор цветов рамки для каждого класса.
1 2 3 4 5 | CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3)) |
Загружаем подготовленную модель
1 2 | print("[INFO] loading model...") net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"]) |
Запускаем считываение с камеры
1 2 | print("[INFO] starting video stream...") vs = VideoStream(src=0).start() |
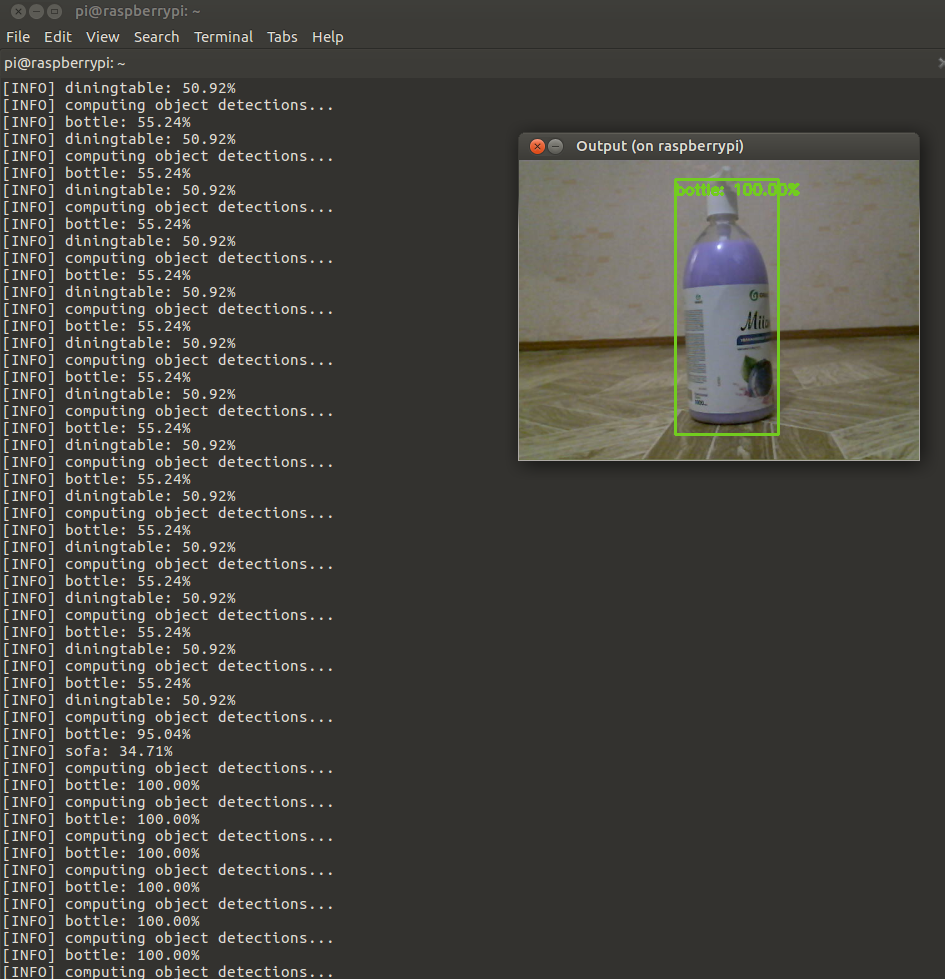
В цикле перебираем все фреймы и распознаем:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | while True: try: frame = vs.read() image = imutils.resize(frame, width=400) (h, w) = image.shape[:2] except: vs.stop() time.sleep(2.0) print("[INFO] starting video stream...") vs = VideoStream(src=0).start() fps = FPS().start() continue #Преобразуем полученое изображение в blob и передаем в нейронную сеть blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 0.007843, (300, 300), 127.5) print("[INFO] computing object detections...") net.setInput(blob) detections = net.forward() # В результате работы сети получаем обнаруженные элементы и выполняем их перебор for i in np.arange(0, detections.shape[2]): #Извлекаем вероятности совпадения. confidence = detections[0, 0, i, 2] # Убираем ложные вероятности (те которые достаточно малы) if confidence > args["confidence"]: #Извлекаем индекс метки класса из `detections`, #И вычисляем координаты ограничивающего прямоугольника. idx = int(detections[0, 0, i, 1]) box = detections[0, 0, i, 3:7] * np.array([w, h, w, h]) (startX, startY, endX, endY) = box.astype("int") #Отображаем предположения label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100) print("[INFO] {}".format(label)) cv2.rectangle(image, (startX, startY), (endX, endY), COLORS[idx], 2) y = startY - 15 if startY - 15 > 15 else startY + 15 cv2.putText(image, label, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2) #Выводим фрейм на экран! cv2.imshow('Output', image) key = cv2.waitKey(5) & 0xFF # Ждем нажатие клавиши q и завершаем цикл. if key == ord("q"): break fps.update() # do a bit of cleanup print("[INFO] cleaning up...") cv2.destroyAllWindows() vs.stop() |